The Data Engineering Docker-Compose Starter Kit
We’ve all been there. Starting a new data engineering project and, instead of diving right into the fun stuff, we’re stuck setting up configurations. Again.

So, I’ve put together a Docker Compose config with a bunch of services you’ll often see in data engineering projects. Just pull it up on your computer and you’re all set to kick off your own thing. Now, instead of building from scratch, you can jump straight into the action.
Hint: If you don’t know what Docker and Docker Compose are, now’s the perfect time to go find out.
Why We’re Here and What’s the Deal
Here you can find my starter kit that includes the following services/tools:
- RedPanda: Think of it as your data’s personal post office. It’s similar to Kafka, but many say it’s cooler. You send data in, and RedPanda makes sure it gets to where it’s supposed to go, all in real-time. Ideal for managing loads of data and crafting event-driven applications.
- Python Consumer Service: This is a tool that’s always active, monitoring specific topic from RedPanda. It grabs incoming data and takes action. For now, I’ve set it to store messages in a table in MySQL, but you can customize it to do much more complex tasks.
- MySQL: You’ve probably heard of it, super popular. Great for when we need to keep things organized and query data quickly.
- S3 (Minio): It’s our digital storage room. Just like Amazon’s S3, but we can set it up on our local machines for free.
- Mage.ai: Consider it the coordinator for all our data activities. It’s similar to Airflow but sports a fresher look and added flair. It sets the when and how for data tasks, making organization simple and stylish.
- Jupyter Notebook: It’s like our digital lab notebook. We can write code, run it, and see the results all in one place. Makes experimenting and playing with data super fun and easy.
So, with all these tools combined, we’re basically setting up a state-of-the-art digital workshop to handle, play with, and make the most out of our data. Fun times!
Data’s Dance Across the Stage
Now, let’s transition and focus our attention on Docker.
Docker lets you create, ship, and run applications inside containers. These containers pack everything an application needs from libraries to dependencies. So, when you move your application to a different machine with Docker, it just works. No more “it works on my machine” headaches.
So, what happens when our application has a bunch of containers? Enter Docker Compose.
Docker Compose is like a coordinator for a multi-container orchestra. Instead of manually creating and managing individual containers, developers can define their whole setup in one file: docker-compose.yml. This file lists all the services, networks, and storage spaces our app needs. And the best part? One command, docker-compose up, brings the whole setup to life.

Now that we’ve talked about the power of Docker and the organizing genius of Docker Compose, you’re probably wondering how to get all this magic working on your machine. Good news: I’ve made it super easy for you. The next steps will guide you through running my ready-to-use docker-compose.yml file.
First, let’s create a file for passwords and secrets in the root folder of the project. This file has already been added to the .gitignore file, so it won't go public.
touch .secretsInside the .secrets file, we'll store the password for the MySQL database and save it.
MYSQL_ROOT_PASSWORD=very_strong_passwordTime to get things rolling. Execute the command docker-compose up from terminal and see it all come to life.
In just a few moments, here’s what you’ll have ready and waiting:
- RedPanda UI: Accessible at
localhost:8080. You'll find a pre-created topic named "my-topic". - Mage: Head to
localhost:6789to see "my_project" already set up for you. - Jupyter: Launch it at
localhost:8888and you'll find a notebook titled "my-notebook.ipynb". - Minio: Visit
localhost:9001and inside you'll discover a bucket named "my-bucket" with a "data.csv" file. - MySQL: Available at
localhost:3306, there's a database named "my_database" waiting for you. - Python Consumer Service: This is working behind the scenes and will create a “sessions” table in the “my_database”.
For illustration purposes I’ve set up two data flows to highlight how these services interact. You’re free to configure them as you wish.
- Event-Driven App Flow: Stream events into the Python service and record them in MySQL.
- ETL Flow: This involves a data pipeline in Mage. Here’s what it does:
- Reads files from s3 (using Minio)
- Aggregates data with pandas
- Saves results to MySQL
- And as a bonus, you can explore the data in Jupyter, ideal for data analytics and scientists.
First flow: RedPanda -> Python Consumer Service -> MySQL table
Head over to RedPanda at http://localhost:8080/topics. You’ll notice the “my-topic” is already set up for you.
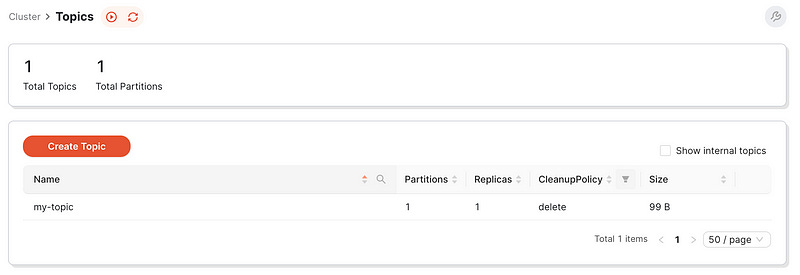
Click on “my-topic”, then select “Publish message”.
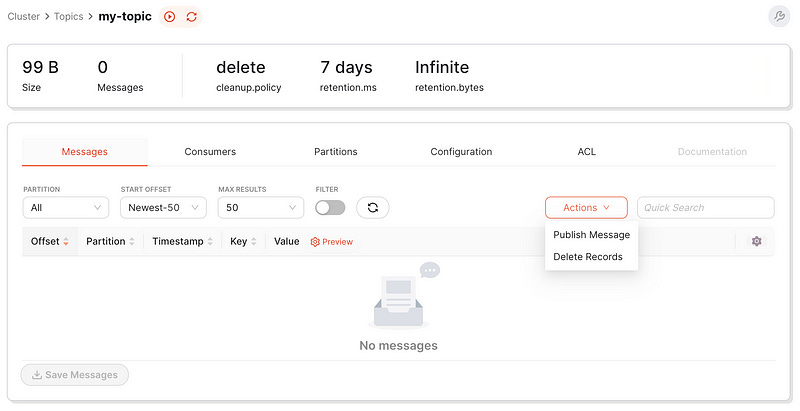
When you publish a message, our Python consumer service will record it in the table defined in the code block below. You don’t need to provide an ‘id’ since it auto-increments. Also, ‘session_id’ is automatically generated. So, all you need to send is a JSON with the ‘user_id’ like this: {"user_id": <your_int_value>}.
class Sessions(Base):
__tablename__ = 'sessions'
id = Column(Integer, primary_key=True, autoincrement=True)
session_id = Column(String(255), default=uuid_gen, nullable=False)
user_id = Column(Integer, nullable=False)Go ahead and send a test message.
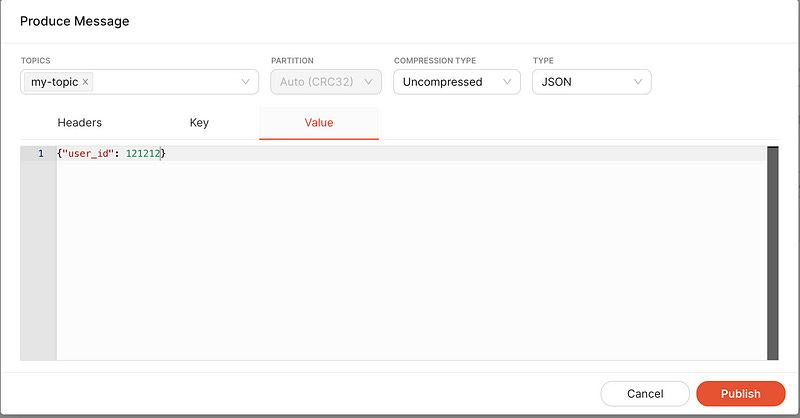
Great, as you can see the message is published.
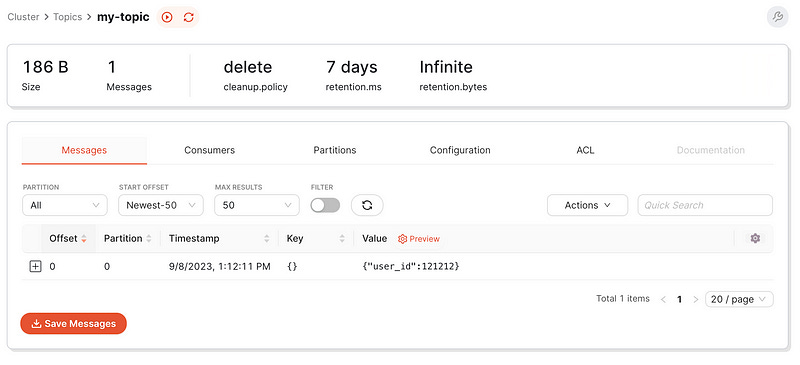
If you have Docker Desktop installed, check the Python consumer service log. You should spot our recently published message there.
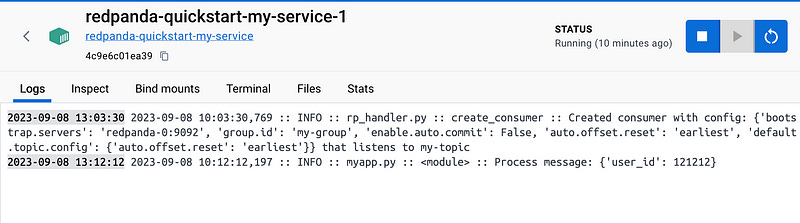
Alternatively, you can achieve the same using the command line with docker ps and docker logs commands.
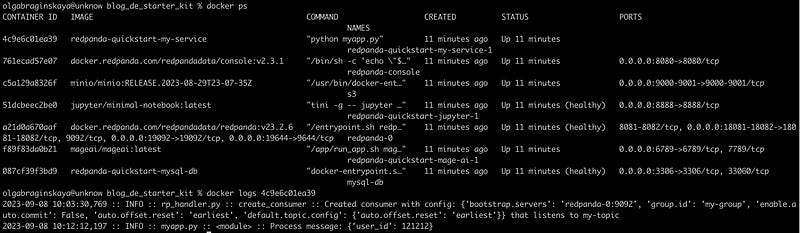
Let’s inspect the database.
Install DBeaver community version on your computer and launch it. Your new connection settings should resemble the following:
Host: localhost
Port: 3306
Database: my_database
Username: root
Password: very_strong_password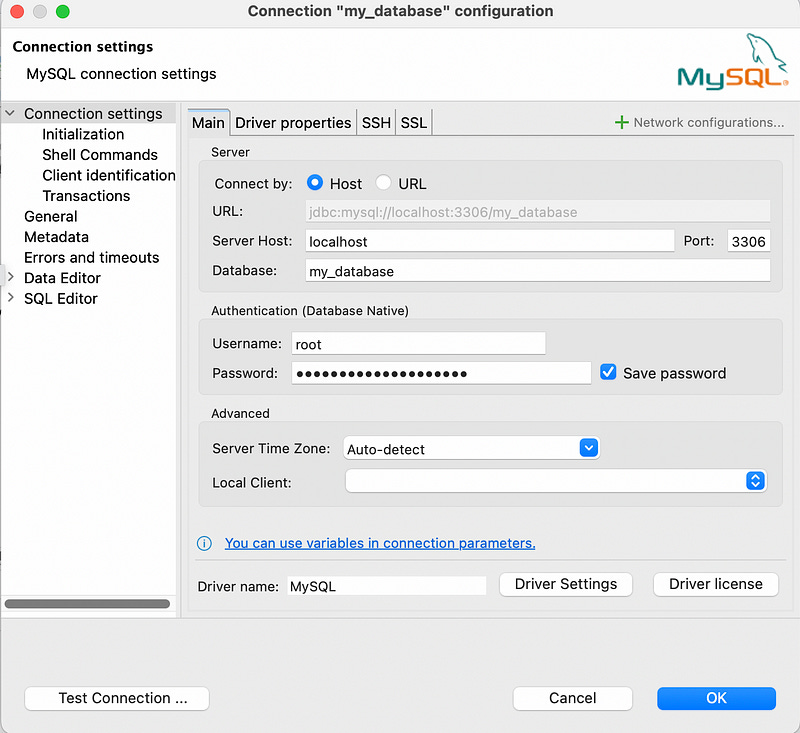
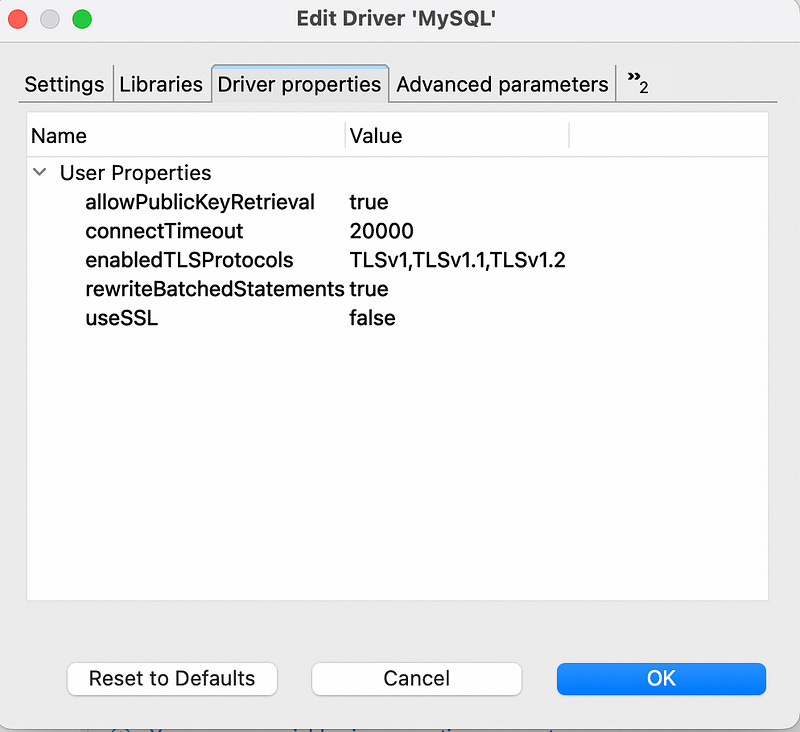
Additionally, navigate to “Driver Settings” -> “Driver Properties” and input the settings as shown in the screenshot below:
If you’ve set up the connection correctly, this is what you should see:
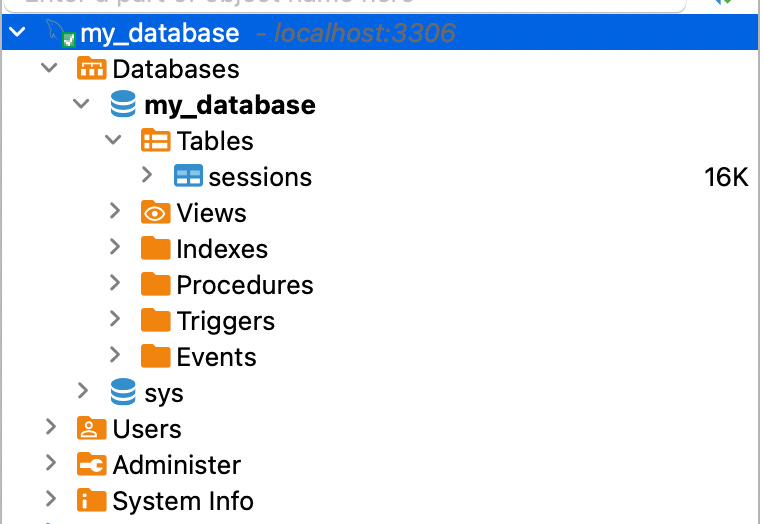
You’ll likely observe that the “sessions” table already exists. Let’s run a query on it.
SELECT *
FROM my_database.sessions;And the result:
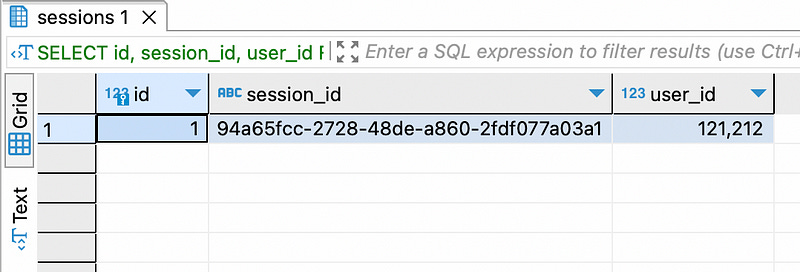
Done! We can see our test message.
Second flow: S3(minio) -> Mage -> MySQL -> Jupyter Notebook
Access Minio at http://localhost:9001/login. Use both the username and password as “minioadmin”. Once logged in, you’ll find our pre-created bucket containing a file.

The “data.csv” file contains historical weather data from Tel Aviv, sourced from another article I wrote. If you wish, you can swap it with a public dataset, for example, from here.
Next, navigate to Mage at localhost:6789. Inside, you’ll discover a pre-established “my_project” containing a single pipeline named “my_pipeline.”
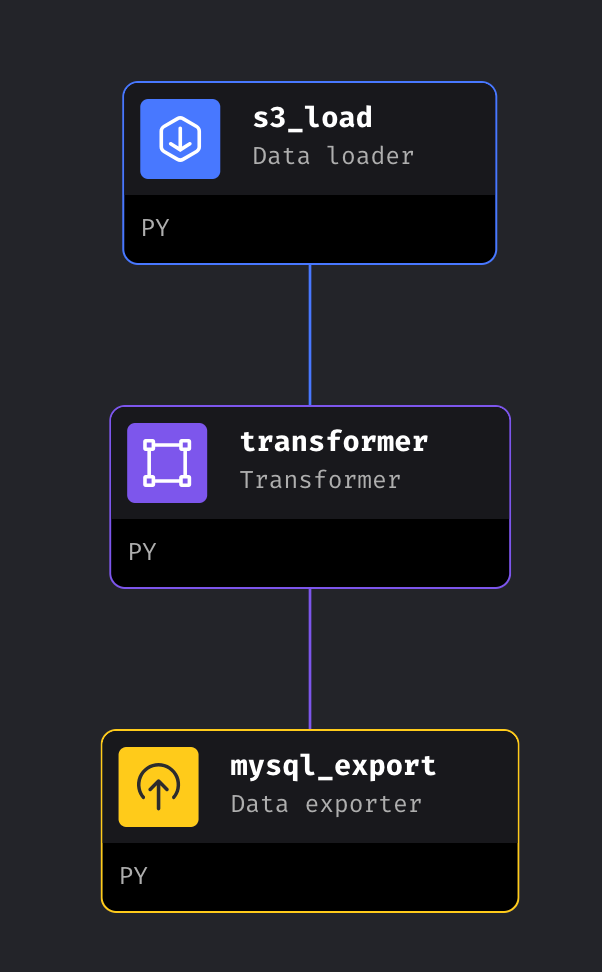
Upon inspecting the pipeline, you’ll notice its workflow: it goes from S3 load to a transformer (pandas) and finally to MySQL export.
By clicking “Edit” on “my_pipeline”, you’ll be presented with all the associated files and the code for each step.
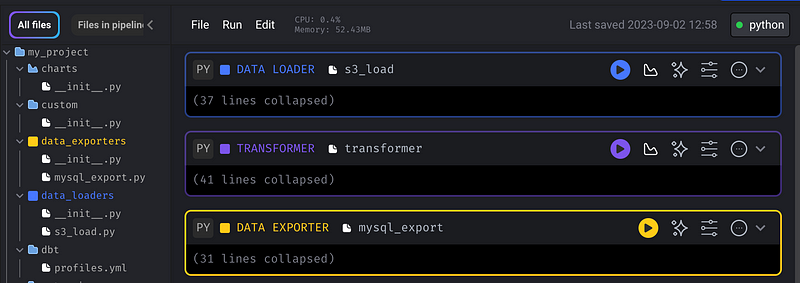
You might wonder how Mage recognizes connections to S3 or MySQL. In the list of files on the left, there’s an io_config.yaml file detailing these connection settings. Within it, there's a MySQL section pointing to my_database and an AWS section for Minio.
version: 0.1.1
default:
# Default profile created for data IO access.
# Add your credentials for the source you use, and delete the rest.
# AWS
AWS_ACCESS_KEY_ID: ""
AWS_SECRET_ACCESS_KEY: ""
AWS_REGION: us-east-1
AWS_ENDPOINT: http://minio:9000
# MySQL
MYSQL_DATABASE: my_database
MYSQL_HOST: mysql-db
MYSQL_PASSWORD: very_strong_password
MYSQL_PORT: 3306
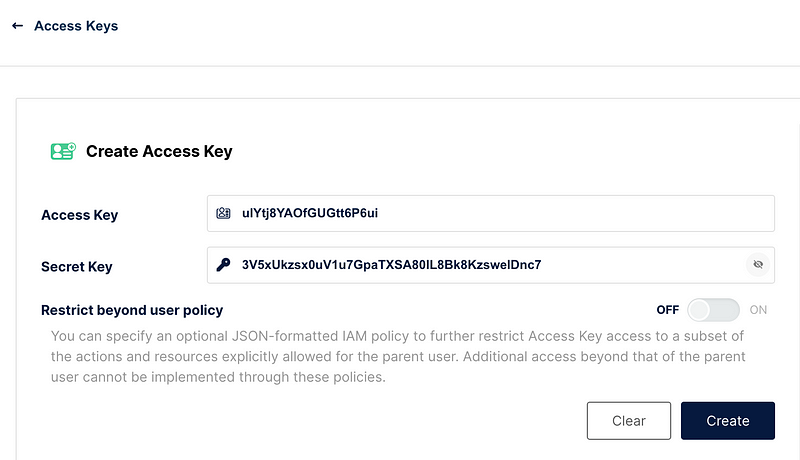
MYSQL_USER: rootBefore you run this pipeline, ensure you’ve set up your own AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY in Minio.
- Navigate to http://localhost:9001/access-keys and select “Create access key”.
- Copy the provided values into your
io_config.yamlunderAWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY. - Click the “Create” button and ensure you save the
io_config.yamlfile.
Next, let’s set up a new table in MySQL. Open DBeaver and execute the following query. While Mage can auto-generate tables, I want to ensure this table remains consistent for all readers.
CREATE TABLE `mytable` (
`station` text,
`_year` text,
`tmin` decimal(10,2) DEFAULT NULL,
`tmax` decimal(10,2) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ciStart the pipeline by visiting http://localhost:6789/pipelines/my_pipeline/triggers and click on “Run pipeline now.” You should see a green indicator, signaling success.

While you can look at the pipeline code for details, here’s a summary: It first fetched our data.csv from s3 during the s3_load step. Subsequently, it performed some transformations using pandas in the transformer step.
# Filter out rows where TMIN or TMAX is NaN
df = data.dropna(subset=['TMIN', 'TMAX'])
# Create a 'YEAR' column
df['YEAR'] = df['DATE'].str[:4]
# Group by year and compute average TMIN and TMAX
data = df.groupby(['STATION','YEAR']).agg({'TMIN': 'mean', 'TMAX': 'mean'}).round(2).reset_index()
return dataQuick heads-up: What I’m doing in the code above from transformation step is setting up data for a graph we’ll create in a Jupyter notebook. Specifically, I’m calculating the yearly average for both minimum and maximum temperatures, grouped by station and year.
Finally, in the third step, these results saved to a MySQL table via the mysql_export step, using Mage's connector which you can observe in the code block below.
with MySQL.with_config(ConfigFileLoader(config_path, config_profile)) as loader:
loader.export(
df,
None,
table_name,
index=False, # Specifies whether to include index in exported table
if_exists='append', # Specify resolution policy if table name already exists
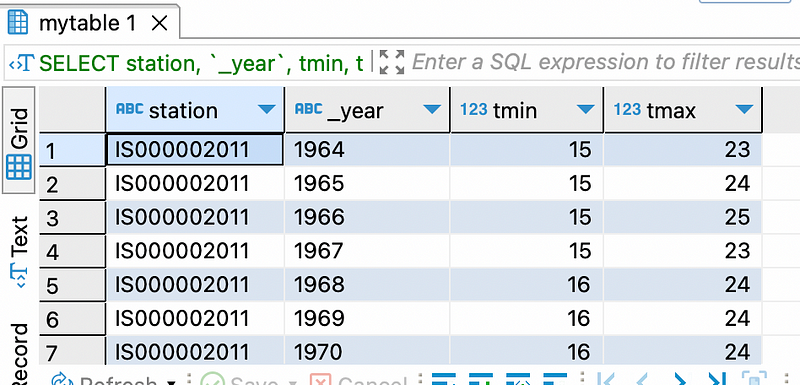
)Now, let’s verify the data in MySQL. In DBeaver, refresh my_database and then run a query on mytable.
SELECT *
FROM my_database.mytable;This is our aggregation.
Now, let’s explore this data further. Launch Jupyter Notebook localhost:8888. Inside, you’ll find a pre-established notebook. Go ahead and click on it.
Inside the notebook, you’ll find some code. It essentially connects to the mytable table in MySQL, loads the data into a pandas dataframe, and then utilizes the plotly module to render an impressive graph.
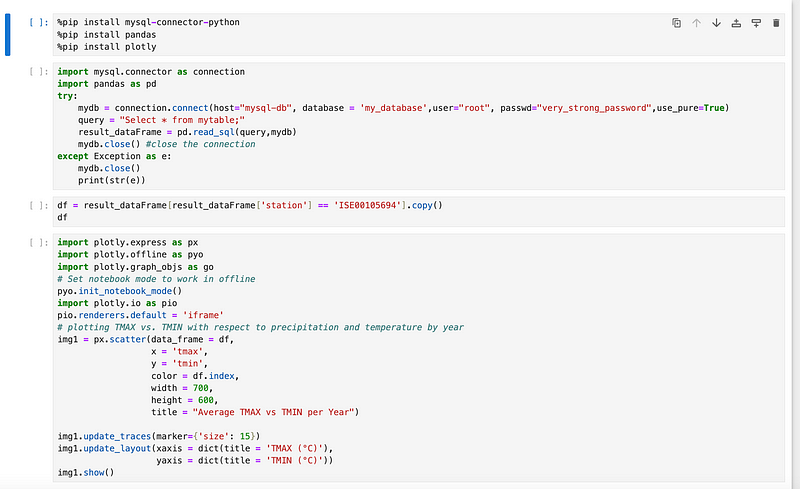
Execute each cell sequentially, and by the end, you’ll see the result. If you’re curious about the graph’s details, check out the explanation here
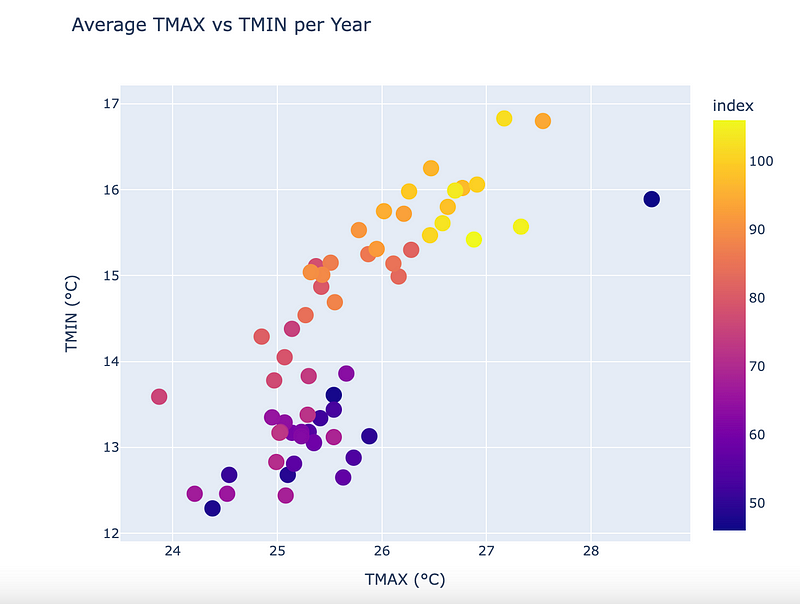
Amazing, right?

Dressing Up Your Docker Config for a Perfect Fit
Ready for more? Here are additional ways you can leverage these services:
Alerting and Notification System:
- RedPanda captures real-time metrics or logs from applications.
- The Python listener checks for specific conditions or thresholds. If something looks off, it triggers an alert.
- Mage could then be used to manage these alerts, maybe aggregating them, or pushing them to other systems, or even initiating automatic remedial tasks.
User Behavior Analytics:
- RedPanda streams user activities from a website or application.
- The Python listener processes and enriches this stream with additional user info from MySQL.
- The enriched data lands in S3 (Minio), where analysts can use Jupyter to analyze user behaviors, build funnels, or segment users.
Real-Time Analytics Dashboard:
- RedPanda captures real-time events from different sources, like user activities or sensor data.
- Mage listens to this data, perhaps aggregating data or filtering specific events.
- Processed data is stored in MySQL for structured, quick access.
- A Jupyter notebook fetches this data for analysis and visualization, providing a real-time analytics dashboard for end-users.
Consider adding a Python producer service or producing messages directly from Mage. With Mage, you can even set a trigger to launch the pipeline for every new file on s3. Interested in running a dbt project? You can do it in the Mage pipeline on top of the MySQL database. If MySQL isn’t your favorite, swap it out for Postgres or Mongo. Essentially, there’s a wide range of options for adjusting and enhancing these services.
Also, consider exploring my article about running Argo Workflows locally and another one about partitioning outputs from RedPanda on s3.
Behind Docker’s Doors
Let’s take a look at my repository and look at each service individually.
In the repository, you’ll spot two primary files: docker-compose.yml and docker-compose-infra-services.yml. Executing docker-compose up typically looks for the default docker-compose.yml to kick things off. However, to distinguish third-party services (like Kafka or MySQL) from the actual development environment, I've placed those services in docker-compose-infra-services.yml. This structure lets you run external services independently and develop using pure Python, Go, etc., connecting directly via localhost.
docker-compose -f docker-compose-infra-services.yml up --buildLet’s look at our services one by one.
RedPanda
In the docker-compose-infra-services.yml file, RedPanda is represented by three interlinked services:
- redpanda-0: This is the RedPanda broker itself. When communicating within the same network, you’d use the host
redpanda-0:9092. - console: This serves as RedPanda’s UI and is accessible at http://localhost:8080/.
- redpanda-init: This component waits for
redpanda-0to be ready and then initializes the 'my-topic' topic for us onredpanda-0:9092using topic create -r 1 -p 1 my-topic — brokers redpanda-0:9092
redpanda-init:
image: docker.redpanda.com/redpandadata/redpanda:v23.2.6
depends_on:
redpanda-0:
condition: service_healthy
networks:
- redpanda_network
command: topic create -r 1 -p 1 my-topic --brokers redpanda-0:9092MySQL
In the docker-compose file, MySQL is represented as a single service. However, it has its nuances. One of them is that it uses the .secrets file to pull the MYSQL_ROOT_PASSWORD variable.
mysql-db:
build:
context: .
dockerfile: Dockerfile.mysql
container_name: mysql-db
healthcheck:
test: ["CMD", "mysqladmin", "ping", "-h", "localhost"]
timeout: 20s
retries: 10
ports:
- "3306:3306"
environment:
- MYSQL_DATABASE=my_database
env_file:
- '.secrets'
volumes:
- mysql-data:/var/lib/mysql
networks:
- redpanda_networkYou may also observe that it utilizes a custom Dockerfile, which is shown in the following code block.
# Dockerfile.mysql
FROM mysql:8.1
COPY ./init.sql /docker-entrypoint-initdb.d/The reason behind this is that I wanted to have a precreated database ready from the get-go. This way, you can set up anything you want in MySQL before launching your services, all within the init.sql file in the form of MySQL queries. Feel free to ingest data or make any necessary configurations. Let's take a look at the sql file:
-- init.sql
CREATE DATABASE IF NOT EXISTS my_database;
USE my_database;Minio/s3
It comprises two linked services. The aws service takes care of creating a bucket and uploading the data.csv file from the repository on our behalf. However, you also have the flexibility to create your own buckets and upload data.
minio:
image: minio/minio:RELEASE.2023-08-29T23-07-35Z
container_name: s3
ports:
- "9000:9000"
- "9001:9001"
command: server --console-address ":9001" /data
networks:
- redpanda_network
aws:
image: amazon/aws-cli
container_name: aws-cli
command: -c "
sleep 2
&& aws --endpoint-url http://minio:9000 s3 mb s3://my-bucket --region us-east-1
&& aws --endpoint-url http://minio:9000 s3 cp data.csv s3://my-bucket/data.csv
&& exit 0"
entrypoint: [/bin/bash]
volumes:
- "./local_data:/aws"
environment:
AWS_ACCESS_KEY_ID: "minioadmin"
AWS_SECRET_ACCESS_KEY: "minioadmin"
depends_on:
- minio
networks:
- redpanda_networkMage
This service is quite straightforward. It loads Python sources from mage_src as my_project. Any modifications you make locally in this folder will be instantly reflected in Mage.
mage-ai:
image: mageai/mageai:latest
ports:
- 6789:6789
command:
- /app/run_app.sh
- mage
- start
- my_project
volumes:
- ./mage_src:/home/src
networks:
- redpanda_networkJupyter
This service loads the precreated my-notebook.ipynb file into Jupyter notebooks. You won't be prompted for a password due to the empty NotebookApp.token and NotebookApp.password.
jupyter:
image: jupyter/minimal-notebook:latest
ports:
- 8888:8888
volumes:
- ./jupyter_workspace:/home/jovyan
# disable password for jupyter
command:
- jupyter
- notebook
- --no-browser
- --NotebookApp.token=''
- --NotebookApp.password=''
networks:
- redpanda_networkPython consumer service
The code for this service is located in the python_app folder. It utilizes confluent_kafka for handling RedPanda messages and sqlalchemy for writing to the MySQL table. Essentially, it continuously polls messages from Kafka and persists them in MySQL.
The service waits for both MySQL and RedPanda to be up and running. It then uses environment variables for establishing connections within the code. Additionally, it retrieves the MYSQL_ROOT_PASSWORD from the .secret file.
my-service:
build:
context: .
dockerfile: python_app/Dockerfile
depends_on:
mysql-db:
condition: service_healthy
redpanda-init:
condition: service_started
networks:
- redpanda_network
environment:
- BROKER_URL=redpanda-0:9092
- BROKER_TOPIC=my-topic
- MYSQL_DATABASE=my_database
- MYSQL_URL=mysql-db:3306
env_file:
- '.secrets'
#volumes:
# - .:/home/user/app
restart: on-failure The Show’s Over, But the Journey’s Just Begun
That’s all there is to it. As you work on your data projects, keep this kit in your toolbox — it’s here to simplify your journey and make your data work smoother.